大模型與知識圖譜的融合之路 優勢互補與協同發展
隨著人工智能技術的飛速發展,大語言模型與知識圖譜作為兩大核心支柱,正從各自為戰走向深度融合。它們代表了人工智能知識處理的兩種不同范式,其交匯點正是未來人工智能基礎軟件創新的關鍵所在。本文將探討二者的融合路徑、內在的互補優勢,以及如何通過協同發展,共同夯實人工智能的軟件地基。
一、 殊途同歸:兩種知識范式的交匯
大語言模型以其強大的通用語言理解和生成能力,展現了令人驚嘆的“通才”潛力。它通過海量無標注文本的預訓練,學習到了豐富的語言模式、事實知識和淺層推理能力。其“黑箱”特性、知識難以更新、容易產生“幻覺”等問題也日益凸顯。
知識圖譜則以結構化的方式組織和表示知識,將實體、概念及其關系構建成一個巨大的語義網絡。它具備精確性、可解釋性和可溯源性,是深度推理和精準決策的理想載體。但其構建成本高、覆蓋范圍有限、對非結構化文本理解能力弱,限制了其應用的廣度。
二者的融合,本質上是“隱式知識”與“顯式知識”、“統計關聯”與“邏輯關系”的結合,旨在取長補短,構建兼具廣度、深度與可靠性的智能系統。
二、 優勢互補:構建更強大的智能內核
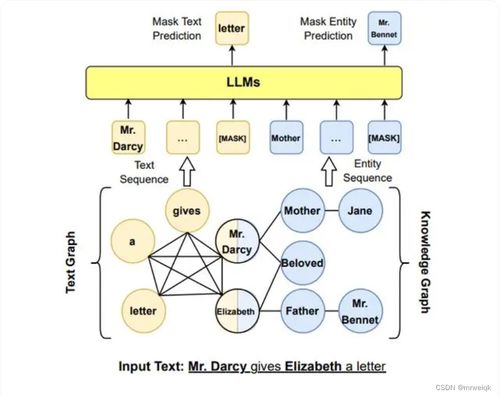
- 知識獲取與增強:大模型可以作為自動化構建和擴展知識圖譜的“超級標注員”。它能從海量文本中高效抽取出實體、關系和事件,極大地降低知識圖譜的構建與更新成本。反之,知識圖譜可以為大模型提供精準、結構化的“知識錨點”,在推理、問答等任務中注入事實依據,糾正其“幻覺”,提升回答的準確性和可信度。
- 理解與推理的躍升:大模型擅長處理模糊、開放的自然語言查詢,理解用戶意圖。而知識圖譜則提供了一條清晰的邏輯推理路徑。結合后,系統能先通過大模型理解問題,再調用知識圖譜進行深度、多跳的邏輯推理,最后用大模型生成流暢、自然的答案。這種“理解-推理-生成”的閉環,實現了從“知道是什么”到“明白為什么”的跨越。
- 動態更新與持續學習:知識圖譜可以作為大模型外部、可動態更新的“記憶體”。當新知識產生時,無需耗費巨資重新訓練整個大模型,只需更新知識圖譜,并通過提示工程或適配器技術讓大模型學會訪問和利用這些新知識,從而實現系統的低成本、高效率的持續進化。
三、 協同發展:重塑人工智能基礎軟件棧
二者的融合并非簡單的功能疊加,而是需要從底層架構上進行深度協同,這正在催生新一代的人工智能基礎軟件。
- 新型數據庫與中間件:傳統的圖數據庫需向支持向量化查詢、與模型深度交互的方向演進。需要開發專門的“圖-模”中間件或協調層,負責在語言模型與知識圖譜之間進行高效的查詢轉換、知識檢索與結果融合。
- 統一的開發框架與工具鏈:未來面向復雜AI應用開發的框架,可能會將大模型微調、提示工程、知識圖譜查詢與推理等能力封裝成統一的API和開發組件。開發者可以像搭積木一樣,靈活組合兩種能力,降低融合應用的門檻。
- 評估體系與治理范式:融合系統需要新的評估標準,既要考核其語言流暢性與創造性,也要評估其事實準確性、邏輯嚴謹性和可解釋性。相應的,圍繞知識來源可信度、更新機制、責任溯源的治理體系也需同步建立。
四、 未來展望:通往可信、可用的通用人工智能
大模型與知識圖譜的深度融合,是通往更可靠、更深刻、更可控的人工智能的必由之路。它不僅能賦能搜索、問答、推薦等現有應用,更將在科學研究(如假設生成與驗證)、復雜決策支持、個性化教育、高端智能制造等領域催生革命性應用。
這條融合之路,要求我們不僅要在算法層面持續創新,更需要在系統軟件、數據工程、評估標準等多個層面協同推進。唯有如此,我們才能構建出堅實、靈活、可信賴的人工智能基礎軟件生態,為通用人工智能的最終實現奠定基石。
如若轉載,請注明出處:http://m.xinteruan.cn/product/46.html
更新時間:2026-01-07 14:01:24